Introducing “Idea Summarization” For Natural Language Processing
Summarize the Most Common “Ideas” Expressed in a Large Text Dataset in a Fully Automated Manner
Introduction
During the summer of 2021, just months after our Chicago-based startup (rMark Bio) working in the healthcare tech space was acquired by Within3, we were in a product integration meeting. The data science department for rMark Bio had just become the data science department of Within3 and we were meeting to scope how our data science services could support the newly merged Within3’s product line and keep us ahead of any competition. One part of that product is a platform for moderated communication between our clients and their customers, so our clients naturally want to know the answer to the question,
“What are our customers telling us?”
I asked
“What is it you want to know about what they are telling you?”
and the response I got was a reframing of the original question that could be paraphrased as:
“What are the most common ideas that people are expressing in this text data that our customers would want to know and act on in a timely manner?”
In that moment, I had no solution to this question.
We had been working in the natural language processing (NLP) space for a few years. We know how to identify distinctive keywords, create text classifications models, use word embedding (like Word2Vec) models to find relationships in text data, build sentiment models, but we had never heard of an automated process that can read a high quantity of text data and output a short, digestible summary of the most common “ideas” expressed in a text dataset in the manner posed. We have since developed a methodology for doing so and would like to present our results here.
In this essay, we’re going to propose an initial version of a methodology that can start with a dataset of text, where each entry is assumed to be very roughly a paragraph in length, the dataset is large enough to necessitate an automated process (at least 100s of entries), and each entry is in response to some central theme. That dataset could be text-based answers to a question, reviews of a product/service, or even a set of social media comments in which we want to identify some inherent thematic structure.
By the end, we will show results for a dataset in which we have inserted multiple ideas being expressed in the form of real user reviews and show that our methodology can reproduce those ideas as results without the need for any a priori knowledge of the content of dataset. Those results will also be concise enough for a human to read and make actionable decisions about, negating the need for anyone to manually read through the text data and summarize it. The process can also be fully automated.
While we don’t presume to be the first to address this problem in this manner, we also have not yet found any other comparable solutions either. Fundamentally, we achieve what we are denoting here as “idea summarization” through the combined use of several existing methodologies in NLP, but we also challenge some assumptions along the way.
Before proceeding further, we note that this essay rests on the foundation of three other essays released on Medium. First, in relation to the topic of K-means clustering, we released a refutation of the “Elbow Method” for identifying the optimal number of clusters inherent to a dataset:
Next, we developed our own methodology for identifying the optimal number of clusters inherent to a dataset in an automated manner and released the results here:
Finally, we also developed a methodology for reducing a series of short text statements that convey roughly the same idea, albeit in different particular wordings, to a single representative statement and released the results here:
The rest of this essay will assume familiarity with these three, but the casual reader can read this essay stand-alone to contextualize the results presented at the end.
“Ideas” For NLP
We introduced a methodology that we denote “Idea Condensation” in a different essay here. Idea condensation will be a critical component of our overall “idea summarization” methodology and in that essay we defined an “idea” from an NLP perspective. We’ll review that here by building from some common NLP principles.
The field of NLP involves the studying of language data with mathematical and statistical techniques; if we can translate a language dataset into a numerical form, then we can use existing quantitative analysis techniques to describe that data. Before we can address what an “idea” is for our purposes in this study, we need to address some common techniques in NLP that allows us to detect structure in text data.
n-grams
A “term” in English NLP is typically a single word (“the”, “cat”, “runs”, “away”, etc.), but can also refer to compound words like “living room”, “full moon”, “Boston Globe” (a newspaper), or even the term “natural language processing” (a three-word compound word) itself. “Boston Globe”, for example, is a singular noun that refers to a newspaper and so a single “term” apart from “Boston” (a city) and “Globe” (a representation of the Earth found in classrooms). Identified terms are also often referred to as “n-grams” in NLP, where “n” refers to the number of words comprising the term. “Cat” is a term comprised of one word and so can be denoted a “unigram”; “Boston Globe” is comprised of two words and so can be denoted a “bigram”; similarly, “natural language processing” is a “trigram” (we rarely, if ever, consider n > 3 terms).
Tokenization
Next, “tokenization” in NLP is, in its most general form, the process of taking a sequence of textual characters and partitioning them into a sequence of pieces, where each piece itself is denoted a “token”. “Term tokenization” is then the more specific case of taking a sequence of text data and breaking it into a sequence of individual terms by our definition above. Bigrams and trigrams are often identified by count statistics of the words comprising them occurring together and setting an arbitrary threshold. For example, suppose we are considering a document in which the terms “Boston” and “Globe” each occur five times, but every time they do occur it is in the sequence “Boston Globe”, then we might want to consider that a bigram for the newspaper “Boston Globe” and not references to city or spherical map.
Part of Speech (POS) Tagging
With term tokenization, we can translate the string of characters
“The cat runs through the Boston Globe.”
into a one-dimensional array of terms
["the", "cat", "runs", "through", "the", "Boston Globe"]Now we can tokenize some text data into a sequence of terms. Part-of-speech tagging (POS tagging) is the technique of assigning labels to individual terms that describe their function in a sentence. In the sentence that we just tokenized, “cat” would be tagged and labeled as a “noun”, “runs” is tagged as a “verb”, and so forth. So, our term tokenized sequence of text data might then look something like
[("the", "determiner"), ("cat", "noun"), ("runs", "verb"), ("through", "preposition"), ("the", "determiner"), ("Boston Globe", "noun")]In practice, a noun would be tagged with a shorthand like “NN” instead of “noun”, a verb would be tagged “VBZ” instead of “verb”, and so forth, but we need not delve into that here. We will be using the SpaCy POS tagger in this study.
Dependency Parsing
With text data tokenized and POS tagged, we turn next to the topic of how terms in text data relate to each other. The term “runs” is an action that is being performed by a noun “cat”. Since the “cat” (noun) is performing the action “runs” (verb), the “cat” is the “subject” of the verb “runs”. The verb “runs” depends on the noun “cat” to make sense. Verbs not only have subjects performing actions, they also have “objects” on which that action is performed.
Note that “the cat runs” seems like it just barely makes the cut for an idea because it is reflexive — both the subject and object of the verb are “cat”. The fully formed thought is “the cat runs [itself] through the Boston Globe”.
The verb “runs” also happens somewhere in this idea. The running is happening “through” (a preposition) the “Boston Globe” (the object of the preposition).
Note that in English “prepositions” and “postpositions” are collectively denoted “adpositions” and so the preposition “through” will be assigned the POS tag “ADP” below. Because the object of the preposition “Boston Globe” follows the adposition “through”, it is more specifically a “preposition”. If the object of the adposition precedes the adposition, it is a “postposition”.
All the terms of this sentence form an idea because there is an inherent relationship structure among them. In computational linguistics, this set of relationships is called a “dependency tree”. Here’s an example of a visualization of our sentence with the dependency relationships illustrated
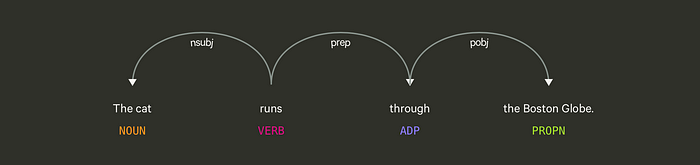
The process of identifying these relationships is called “dependency parsing”. We will be using the dependency parser of the SpaCy python package.
Defining an “Idea” for NLP
With these techniques, we can address the problem we’re trying to solve. When a client comes to us with a set of text data and asks us “what are the main ideas that the responders are telling us?”, we must first ask ourselves “what is an ‘idea’ in NLP?”. We could not find any standard definition for an “idea” from an NLP perspective, so we’re proposing one.
Intuitively, an “idea” needs to be more than just any single term. “Cat” is just a noun and “runs” is an action or verb; neither fits an intuitive notion for a fully formed idea. “Cat runs” almost like an idea and “the cat runs” seems like the bare minimum of a singular, fully formed thought. Pairs of words, like “white dog” (and adjective and the noun that adjective describes, absent any action) or “eats food” (a verb and the object noun that the verb is acting on, absent the subject noun performing the verb) also do not quite make the cut for a fully formed idea.
Compound sentences, however, intuitively seem to go too far. Consider
“The cat runs through the Boston Globe and then he hides in a box.”
This sentence is still fairly short, but contains two fully formed ideas: one idea of an animal running though a place and another of the same animal hiding in a more specific place. Sentences, in general, are too long to represent singular ideas.
So, to represent a singular idea, we’re looking for something more than individual terms or even pairs of terms, but something less than a general full sentence that frequently contains more than one idea. We settled on representing an “idea” as an English language clause, whether dependent or independent, for our purposes in NLP. “Clauses are units of grammar that contain a predicate (verb) and a subject (noun).”
Thus, with our term tokenizer, POS tagger, and dependency parser we identify singular ideas in text data by starting with a single verb and its subject and object nouns. Those nouns and verbs may also then have adjectives or adverbs describing or modifying them and so should be included. Further, adpositions that relate to verbs, such as in our example above, should also be included. An “idea” will be defined by a sequence of terms matching this pattern using the POS tagging and dependency parsing just described.
The Coffee and Bedsheets Reviews Dataset
When building models, having testing and validation datasets is always critical for verifying the degree to which, and in what context, the model can produce a result from the data it processes. Unsupervised training models can be more difficult to verify than supervised training models because, by definition, there are no correct answers or labels to which each input data point is associated. Unsupervised training attempts to detect structure inherent to the dataset being processes, so we can test them by inserting the kind of structure that we want to be able to detect and then verifying that our modeling techniques can reproduce that.
In our essay “Introducing the “Factionalization Method” For Identifying the Inherent Number of Clusters in a Dataset”, we used several pseudo-datasets in which we generated a known number of clusters of data and then demonstrated an automated technique for detecting the number of data clusters in the dataset, followed by a use of K-means clustering to partition the dataset into that number of mutual exclusive subsets.
For our purposes in idea summarization, we need to start with a text dataset that is representative of the problem we are trying to solve.
In that spirit, we constructed a dataset of 500 paragraph-length user reviews copied from Amazon. 250 of the reviews were related to a particular brand of coffee and 250 were related to a particular brand of bed sheets. 70% of the coffee reviews were positive in sentiment and related to the smell of the coffee while the other 30% were negative sentiment reviews about the acidity/bitterness of the coffee. 70% of the bed sheet reviews were positive sentiment reviews about the sheets being comfortable while the other 30% were negative sentiment reviews about the sheets having a terrible smell straight out of the packaging.
Just a few examples of these reviews are:
“medium roast, with the acidic aftertaste. Our generic Mr. Coffee has an option for a “”strong brew”” which Hubby uses for me. I do not highly recommend.”
“The acidity was too weak for my tastes. I prefer my coffee to really pack a punch.”
“I think that this Honduran has more acidity than the Java, but both feature wonderfully robust flavors that work great as espresso or drip coffee. All of the coffees from Fresh Roasted Coffee, Llc, are amazingly fresh and they fill the kitchen with amazing coffee aroma when I start the grinder.”
“Buttery soft, a little on the warmer side rather than cool, but SO comfortable. Definitely get your bang for your buck.”
“The smell was as if these sheets came from a chemical factory built on top of an active landfill and sewage plant.”
We will see in the process of executing our idea summarization methodology on this dataset that the text contains expressions of the four ideas we have built into it, but there will also be extraneous noise text that we need to distinguish expressions of those ideas from. Each individual text data point is representative of how real people actually write in practice, because they were written as such. So, even though we know the answers we want our idea summarization methodology to find, we ensure it can do so in realistic scenarios — not just idealized datasets in which all data points are written with complete sentences and correct grammar.
By the end of this essay, we will show automatically generated results that reflect these ideas that were built into the dataset, but written with realistic and common language.
Clause Tokenization
We have decided to use English language clauses as a proxy for an “idea” for NLP purposes. As such, we built a custom clause-tokenizer. For example, if we have a sentence like
“This coffee has a really pleasant aroma, however it is a bit acidic. “
the clause tokenizer will break it into two strings like this
“This coffee has a really pleasant aroma”
“It is a bit acidic”
We have broken a single sentence string expressing two ideas — one about coffee smelling good and another about the coffee having an acidic taste — into two strings. Each of those two strings represents a single idea.
Every entry of an input dataset goes through clause tokenization as the first step of the idea summarization process.
Vector Representations of Text Data
After clause tokenization, we are left with a text dataset comprised of larger quantity of shorter idea-sized strings of text. We want to run K-means clustering on this latter dataset, but we first need to translate each idea-sized string of text to a vector form that the K-means cluster can process.
There are a variety of ways to translate text to a vector form, including one-hot encoded vectors, keyword-score encoded vectors, and word embeddings like Word2Vec. The choice is surely to inspire debate amongst data scientists, but we found that using a Term Frequency-Inverse Document Frequence (TF-IDF) model built on a corpus of representative English language documents to compute term scores and construct vector representations was by far the most effective approach.
To construct vector representations of text using a TF-IDF keyword model, we select some number of terms N_TERMS (N_TERMS = 50K or N_TERMS = 100K is typical), assigned an integer unique identifier to each term, then represent every clause-length string of text by a vector N_TERMS long. Each place of that vector corresponds to the term that has been assigned that integer index. In that place is a TF-IDF score corresponding to that term. Any place in the vector for a term not represented in the text is assigned a value of 0.0 .
For example, the clause-tokenized text above
“It is a bit acidic”
would be translated to a vector that might look like

where 0.23 is a TF-IDF keyword score for the term “it”; 0.54 is a TF-IDF keyword score for the term “is”; and so on. Other terms like “the” or “cat” or anything else that does not appear in the text is properly assigned a value of 0.0 by default, which is consistent with the meaning of a TF-IDF score for a term that has a term frequency of zero in the text.
As such, we are left with a numerical dataset of N_TERMS-length vectors (effectively) that are admittedly very high dimensional. Nevertheless, we can still effectively execute K-means clustering on this vector-representation of text dataset. I will note that, for the sake of computational efficiency, there are ways around literally storing in memory and performing vector algebra on vectors that are 50K or 100K elements long, but comprised of mostly zeros.
Identifying Text Clusters With Unsupervised Training
We now have a numerical dataset representation of the original text dataset. In the N_TERMS-dimensional vector space that these data points are represented, the dimension representing each term is mutually orthogonal to the dimension representing every other term. More distinctive and repeated terms that generate higher TF-IDF keyword scores will therefore have higher magnitudes along their respective dimension going into the unsupervised training.
While there are a variety of unsupervised training option available for identifying clusters within a dataset, the K-means clustering algorithm is by far the most common and direct. We found that it works well for our purposes, but have not yet progressed to the point where we have objectively compared it to other options.
In the execution of a K-means clustering algorithm, one must specify up front the number of mutually exclusive categories that a dataset is to be partitioned into (K). If there are “clusters” or “tight groupings” of data points within the dataset, then K-means clustering will find an optimal way to partition the dataset into K discrete and mutually exclusive subsets according to those clusters inherent to the structure of the dataset.
K-means clustering does not, however, determine the optimal number of clusters within a dataset, which is why that K value must be specified up front. After surveying the limited existing options for identifying the number of clusters inherent to a dataset, doing so in an automated manner, and a manner that is reasonably resilient to high-dimensional and noisy data (which is what we get when translating text data to vector representations), we settled on designing our own methodology from first principles. We denote this the “Factionalization Method” and separately present it here.
In the Factionalization Method, we start by designing a metric that achieve a maximum value specifically when the K-means clustering algorithm is executed for the correct number of clusters inherent to the dataset. We developed and tested this methodology with pseudo-datasets in which we constructed an unambiguous number of clusters to be found, then verify that the methodology can correct identify that value. The K-means clustering algorithm must be executed over a range of K values to search for the particular K at which the Factionalization metric is at a maximum. However, because real datasets contain both clusters and potentially a lot of noise, simply choosing the K value at which the Factionalization metric has the highest value is not ideal. Rather, we must use a machine learning fit of a function custom designed to model the shape of the Factionalization metric charted over a range of K values, then identify the maxima of that fitted function in an automated manner. As such, this technique can be fully automated to generate high quality estimates of the number of clusters inherent to the noisy and high-dimensional datasets we are modeling here.
When we execute our optimal K identification methodology on the Coffee and Bedsheets Reviews dataset, we get the following charted results for the Factionalization metric and the function fit to it

This tells us that the optimal number of clusters inherent to the dataset is estimated to be K~13. Note that we specified earlier that we intentionally built four ideas into this dataset, but that there would be extraneous noise as well.
We will find that, in practice, our current version of idea summarization will automatically identify a slightly more granular view of these clusters of ideas and that the noise data will migrate to clusters that simply return lower quality (as ranked by the quality of the constructed output) results that can be properly ignored. Still, our idea summarization methodology will be able to read a dataset of 500 user reviews and produce a properly representative output of its structure that can be read and understood in seconds.
Idea Condensation
The result of the unsupervised training is that the clause-length text dataset has been partitioned into some number of subsets, where that number was automatically identified by the Factionalization metric and fit described in the previous section. Each of those subsets, if properly identified, will contain text statements with similar wording. This is where another methodology that we developed in-house comes into play. We denote this “idea condensation” and write about it here.
In “idea condensation”, we take as input multiple idea-sized strings of text (or clauses, in practice) that express roughly the same idea, albeit with differing exact wordings, and output (1) a single constructed statement that best represents the whole of the input, and (2) the particular input that best represents the whole of the input. This is achieved through a combination of existing NLP methodologies of part-of-speech tagging and dependency parsing, both of which are expounded in our essay on the topic.
Part-of-speech tagging is used to identify the most common terms for various parts of speech, such as the most common noun, the most common verb, and most common adjective in the input text. Dependency parsing is then used to identify possible relationships amongst those most common terms. Using those identified relationships, full idea-length statements that are representative of the input text can be constructed, but the quality is not guaranteed. The more similar the individual inputs are, the more likely a high quality single statement representing the input can be constructed. If the inputs are not similar, then there is no similar message amongst them and no representative statement can be constructed.
Each of the 13 identified clusters of text from the previous section are processed through idea condensation to produce results. There is a ranking system built into idea condensation to judge the quality of the output of each clusters of text; some are better than others. Some clusters of text clearly center around an idea being expressed and so output a highly ranked result, while others are clusters of the leftover noise data that output lower ranked results. By retaining, in the end, only highly ranked results, we are left with a concise summary of the original dataset.
Let’s look at some examples of what idea condensation achieves on a few clusters of text data from the Coffee and Bedsheets Reviews dataset.
Weird Smelling Bed Sheets Straight out of the Packaging
One of the text clusters picked up on language related to an unidentified object having a weird smell. They are in reference to the bed sheets coming out of the packaging having a weird smell. There are also a sprinkling of ideas that came from positive reviews about the smell of coffee, indicating some overlap in the space of these two groupings of text. The idea condensation methodology is resilient enough to noise to piece together what most of the comments are saying without getting distracted by a small number of extraneous data points.
"i love the smell first thing in the morning"
"smell"
"horribly overburned taste and smell"
"smell and taste good"
"it is light brown in color and you can smell the acid as soon as you open the bag"
"my wife said smell good"
"smell great"
"they smell weird"
"they smell a bit inky after coming out of the package"
"also they had a slight ‘new smell’ kind of a bad smell"
"strong chemical smell"
"they feel weird and smell a bit like plastic when you take them out of the package"
"they smell weird"
"great smell and taste"
"strong chemical smell"
"after owning them for less than a year they have developed a musty smell"
"weird chemical smell made us choke"
"i live in southwest florida they came with really weird smell"
"it smelled like cat pee when it arrived and i had to wash it 3 times to remove the awful smell"
"the smell was still"
"there was a strong chemical smell when the package was opened (took washing them 3 times to get smell out)"
"they smell like they’ve been in my grandma’s linen closet for 20 years"
"musty smell"
"the smell though"
"they smell terrible"
"with fabric softener and unstoppables and can not get the smell out of them"
"they smell like a combination of antifreeze and mothballs"
"i noticed quite a bit of blotchy discoloration and a strange burnt smell"
"strong chemical smell"
"horrible chemical smell even after washing"
"the terrible chemical smell is still present"
"i'm going to wash them and see if the smell goes away"
"both had this weird smell that took several washes to get rid off"
"they smell like elmer's glue"
"they smell like something rotten"
"muted chemical smell (like an garage at a gas station)"
"they smell terrible"
"when i opened it they smell like perfume/scented detergent and are stained"
"they started to smell"
"rating is 3 stars due to the chemical smell after 2 washes in the past 24 hours after receiving"
"i can’t get the burnt smell out of my dryer and almost burned my condo down"
"terrible petroleum smell out of the package"
"fishy smell from the material even after multiple washings"
"hard to wash off the “new” funky smell"
"these smell like paint"
"the chemical smell was super strong when i took them out of the package"
"they smell heavily like chemicals"
"they smell bad (like petrol)"
"very weird smell"
"they still smell strongly of formaldehyde"
"they came with a really weird smell"
"when i opened i felt a strong smell and after wash the smell didn’t away completely"
"don’t really ever smell clean"
"weird smell"
"i'm not sure what's going on with the smell"
"these have a terrible smell right out of packaging"
"the smell was awful"
"they smell horrible"
"they smell like you just painted a room and it needs to dry"
"i’ve washed them multiple times to try and get the smell out"
"it’s definitely an overwhelming smell"
"the smell really makes my mouth water like pavlov's dog just before my first sip"
"it really emanates an evanescent smell that fills my house and company loves"The POS tagging and dependency parsing found
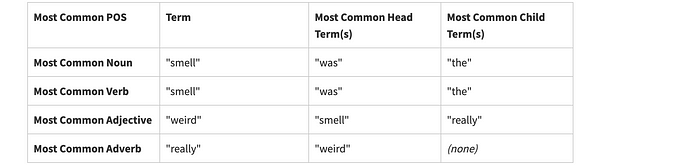
The constructed output from idea condensation is

The particular inputs that best represent the whole of the input dataset are (there was a tie for first place):
“I live in southwest florida they came with really weird smell.”
“They came with a really weird smell.”
Really Comfortable Bed Sheets
This cluster of text was very clearly centered on terminology related to sheets being comfortable, even if every particular statement says so in a slightly different way. Consequently, a high quality output can be constructed.
"these sheets are soft & comfortable to sleep on."
"these are honestly the most comfortable sheets i’ve ever owned."
"the sheets are pretty soft after a few washes and are very comfortable."
"these sheets are lightweight which makes them very comfortable for me."
"both the pillowcases and sheets are soft and very comfortable."
"these sheets are the most comfortable that i've ever slept in."
"the sheets are very comfortable."
"they are comfortable sheets that can withstand summer heat."
"we asked our guest what they thought of the sheets and they said they were very comfortable and soft."
"the sheets and pillow cases are comfortable and i like them a lot."
"now i have these and they are by far the most comfortable sheets i have had in a while."
"these are the sixth set of amazon basics bed sheets i've purchased and they are very comfortable."
"these sheets are soft and comfortable without becoming oppressively hot."
"these sheets are soft and comfortable."
"i was very pleasantly surprised at how comfortable and soft these sheets are."
"these are among the most comfortable sheets i've ever slept on."
"however the feel of these sheets even after washing a few times is definitely comfortable."
"bought these for my guest room for my sister when she is over and they are quite possibly the most comfortable sheets ever."
"the sheets remain comfortable and smooth."
"comfortable sheets in great colors."
"comfortable sheets that will keep you cool at night."
"these sheets are better than the 400 thread count sheets that i have gotten in the past in an effort to be more comfortable sleeping."
"these sheets are extremely soft and comfortable."
"these sheets are soft and comfortable."
"super soft and light weight microfiber sheets are the most comfortable i have ever slept on."
"if you’re looking for comfortable high quality sheets at an affordable price then these are the sheets for you."
"the sheets got softer after the first wash and are very comfortable to sleep on."
"i get really warm when i sleep and these sheets are really lightweight which is comfortable for me."
"very soft and comfortable sheets."
"soft and very comfortable i have gone through a bimbos different sets of sheets and these by far are the ones i love."
"the sheets are super comfortable."
"they're actually very soft sheets and comfortable to sleep on."
"i got these sheets with minimal expectations and was blown away by how comfortable they are."
"these sheets are comfortable and soft."
"these are the most comfortable sheets or fabric for that matter that you will ever experience."
"comfortable sheets."The POS tagging and dependency parsing found
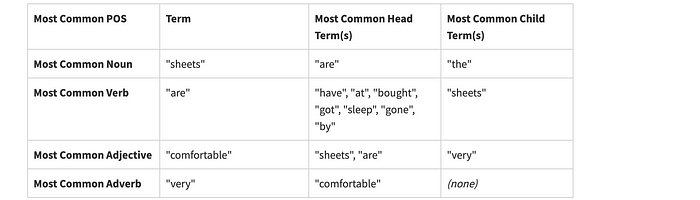
The constructed output from idea condensation is
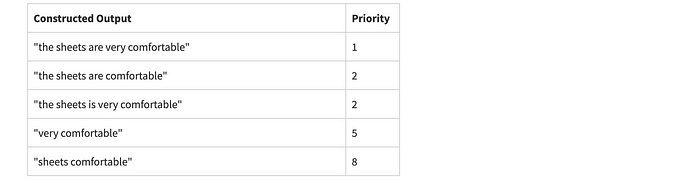
The particular inputs that best represent the whole of the input dataset are (there was an 7-way tie for first place):
“The sheets are pretty soft after a few washes and are very comfortable.”
“These sheets are lightweight which makes them very comfortable for me.”
“Both the pillowcases and sheets are soft and very comfortable.”
“The sheets are very comfortable.”
“These are the sixth set of amazon basics bed sheets i’ve purchased and they are very comfortable.”
“I was very pleasantly surprised at how comfortable and soft these sheets are.”
“The sheets got softer after the first wash and are very comfortable to sleep on.”
Smooth Coffee Beans
Here is the text data from another cluster that appears to have centered around the term “smooth” in reference to coffee. This cluster of text is not as highly populated as the previous two and so there is a 16-way tie for the most common noun, each appearing just once. Still, a somewhat sensible representation is found despite a relatively noisier text data context and fewer entries.
"it’s very smooth.
"it is very smooth and his tummy tolerates more than one cup a day."
"and for me personally really went against what i'm looking for in an espresso - smooth."
"high acidity and not smooth at all."
"very acidic and not smooth."
"it's smooth."
"it is a well balanced bean that finishes smooth."
"creamy) and extremely smooth."
"smooth."
"they're smooth."
"it is very smooth."
"they’re smooth."
"than the smooth full body i am accustomed to with medium and dark roast guatamalan."
"get silky smooth and cleaned up."
"smooth texture with good amount of oils."
"silky smooth."
"it’s very smooth and flavorful."
"very smooth."
"smooth mouth-feel."
"smooth."The POS tagging and dependency parsing found
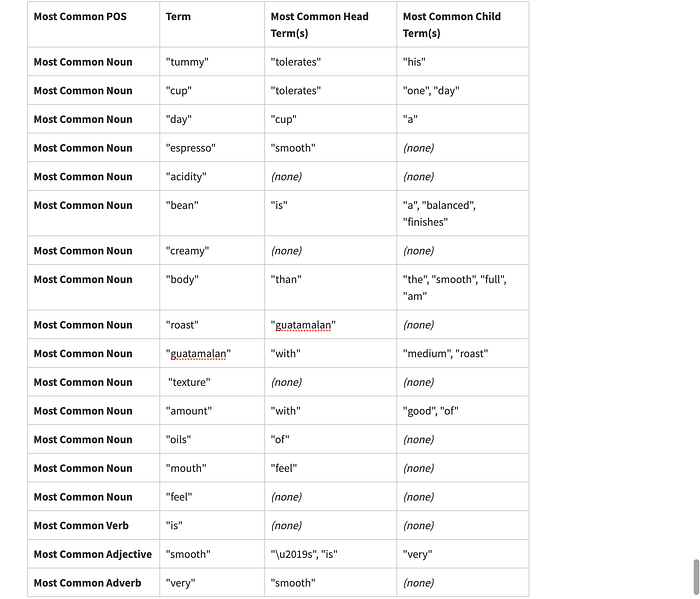
The constructed output from idea condensation is
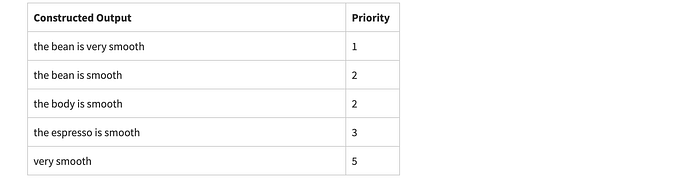
The particular input that best represents the whole of the input dataset is:
“it is very smooth and his tummy tolerates more than one cup a day.”
Results
Finally, suppose we’ve fully processed our Coffee and Bedsheets Reviews dataset through idea summarization. We also decide that we want to look at the idea condensation output of only the clusters that produced a “priority” 1 or 2 result (according to the tables in the previous section). The final summary of this dataset that was processed in a fully automated manner is

Hence, we were able to identify and output these eight ideas with best-representative examples for each. In principle, we can pair this methodology with a suitably trained sentiment model to also gauge sentiment on each idea and example in the output.
Inevitably, there will always be some daylight between distinguishable repeated ideas in a text dataset as judged by human subjectivity and those identified in a purely data-driven algorithmic manner. This initial version of idea summarization detected distinguishable ideas at a slightly more granular level than expected. Nevertheless, the output is concise and each of the four original ideas that were built into the dataset are represented
- coffee that has a great aroma
- coffee that tastes too bitter or acidic
- bed sheets that are really comfortable
- bed sheets that smell weird
with no output ideas appearing that are not clearly related to one of these. What was not represented in the output is any extraneous noise that was not a repeating pattern in the original dataset.
One discrepancy between our intention and the algorithmic detection is between the “the aroma is great” cluster and the “the coffee is really great” cluster. By inspection, the text strings in the former cluster tended to speak in reference to “coffee”, but did not explicitly use that term; meanwhile, the text strings associated with the latter cluster did explicitly mention “coffee”.
Another similar discrepancy was between the “the taste is acidic” and the “the aftertaste is too acidic” clusters, both in reference to the coffee product. In this case, one could argue that the human subjectivity was flawed to not notice the repeated use of a distinct term like “aftertaste” within that collection of text strings, but the machine learning detected a correct interpretation and distinction that a human would have missed.
These are the results of our first experimental version of idea summarization, but we have many methodological improvements queued for development.
Just a few are:
- Exploring forms of unsupervised clustering other than K-means clustering. We fully admit that we started with K-means clustering because it’s simple and straightforward. We make no claim that it is ideal for the scenario in which it is applied.
- Dimensionality reduction may have a role to play given how high-dimensional the vector-represented text data is by virtue of treating every term as mutually orthogonal.
- “Lemmatization” should help (convert terms to base form). Currently, functionally similar words like “taste”, “tastes”, “tasted”, “tasting”, are treated as completely orthogonal terms. Lemmatization would convert them all to “taste” in the vector representation. That makes it easier to cluster text data mentioning any form of “taste” into the same grouping.
- Expanding the set of identifiable and constructible grammatical patterns during idea condensation — both in variety and complexity.
- One valid criticism of the current algorithm is that synonymous terms are not treated as such. For example, the terms “aroma” and “smell” — both of which were used in the positive coffee reviews — are treated as completely independent, orthogonal terms. In the vector space representation of terms, “aroma” is treated equally as linearly dependent from “smell” as it is from any other random terms like “cat” or “car”.
- Better automated grammar checking of the output.
We’re eagerly anticipating improved results as our research and development continues.
Conclusion
The Information Age has produced challenges related to the consumption of data that human culture has never faced before. From the advent of the first civilizations ~10,000 years ago until a few decades ago, our relationship with information was characterized by it’s scarcity and accessibility. Computing technology, however, has suddenly enabled anyone with a personal computer and internet connection to access almost any information that humanity has produced, without regard to context, subject matter expertise, or veracity. Anyone can say any falsehood on a web page styled as professionally as the content of the New York Times or Wall Street Journal with the relative rigor and due diligence of the work behind the respective pages’ contents lacking visibility. The volume of all such content, regardless of its reliability, is beyond that which we are able to consume. This new context of our new relationship with data will necessitate new tools for managing and understanding it, as well as standards for trusting it. Acting on false information, or an incorrect understanding of correct information, creates damage in areas as diverse as business operations and social stability alike. Painful reality checks are inevitable when we act on false perceptions of it.
Powerful tools for producing new language content are rapidly proliferating. Researching better ways to understand the text data that exists will be crucial to navigating the volume of information.
The “idea summarization” methodology introduced in this essay is an attempt to better understand the structure of text data in high volumes. It was designed to help us understand high volumes of short text responses to a moderator’s question. By accurately and efficiently understanding those responses, actionable intelligence can be collected. If a pharmaceutical representative is asking a particular question about a drug and getting thousands of responses from healthcare providers prescribing the drug, a small subset of responses speaking of a repeated side effect could go unnoticed. A manufacturer of bed sheets getting repeated negative reviews related to the bed sheets coming out of the package with a strong chemical smell should want to know about that as quickly as possible. Our intent with idea summarization is to address and solve operational problems like this in a cost-effective manner by accurately understanding complex text datasets quickly.
While this methodology is still in its infancy, even as it largely composed of existing techniques that do not push the limits of current AI research, we hope it also opens new avenues for understanding and managing the large quantities of text data being produced in the Information Age.
We imagine, in time, that text analytics methodologies like this could also be applied to other contexts, like social media posts and comments. Identifying structure within text data in a more useful manner may also help the fight against misinformation/disinformation online as well. Progress in information technology should also be paired with progress in information management and consumption. We hope that idea summarization will contribute.
